
–Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —П–Ј—Л–Ї–∞ MC# –і–ї—П —А–µ–∞–ї–Є–Ј–∞—Ж–Є–є –њ–∞—А–∞–ї–ї–µ–ї—М–љ–Њ–≥–Њ –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А–∞ –Њ–±—А–∞–Ј–Њ–≤.
–Х.–°.–С–Њ—А–Є—Б–Њ–≤
—Б—Г–±–±–Њ—В–∞, 27 —Б–µ–љ—В—П–±—А—П 2003 –≥.
1 –¶–µ–ї–Є –Є –њ—А–Њ–±–ї–µ–Љ—Л
–Ъ –Ј–∞–і–∞—З–µ –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—Ж–Є–Є –Љ–Њ–ґ–љ–Њ —Б–≤–µ—Б—В–Є –Љ–љ–Њ–≥–Њ –њ—А–Є–Ї–ї–∞–і–љ—Л—Е –Ј–∞–і–∞—З : –Њ—В –Њ–њ—В–Є—З–µ—Б–Ї–Њ–≥–Њ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П —В–µ–Ї—Б—В–∞ –і–Њ –≤—Л—П–≤–ї–µ–љ–Є–µ —Д–∞–ї—М—И–Є–≤—Л—Е –Ї—А–µ–і–Є—В–љ—Л—Е –Ї–∞—А—В –Є –Љ–µ–і–Є—Ж–Є–љ—Б–Ї–Њ–є –і–Є–∞–≥–љ–Њ—Б—В–Є–Ї–Є. –°—Г—Й–µ—Б—В–≤—Г–µ—В –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –њ–Њ–і—Е–Њ–і–Њ–≤ –Ї –њ–Њ—Б—В—А–Њ–µ–љ–Є—О –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А–Њ–≤. –Т –і–∞–љ–љ–Њ–є —Б—В–∞—В—М–µ —А–∞—Б—Б–Љ–Њ—В—А–µ–љ –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А –љ–∞ –Њ—Б–љ–Њ–≤–µ –Є—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ–Њ–є –љ–µ–є—А–Њ–љ–љ–Њ–є —Б–µ—В–Є [1]. –Я—А–Є –±–Њ–ї—М—И–Њ–є —А–∞–Ј–Љ–µ—А–љ–Њ—Б—В–Є –љ–µ–є—А–Њ–љ–љ–Њ–є —Б–µ—В–Є, –≤–Њ–Ј–љ–Є–Ї–∞–µ—В –њ–Њ—В—А–µ–±–љ–Њ—Б—В—М –≤ –≤—Л—Б–Њ–Ї–Њ–њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ—Л—Е –Љ–љ–Њ–≥–Њ–њ—А–Њ—Ж–µ—Б—Б–Њ—А–љ—Л—Е –≤—Л—З–Є—Б–ї–Є—В–µ–ї—М–љ—Л—Е —Б–Є—Б—В–µ–Љ–∞—Е [2]. –≠—В–Њ –Њ—Б–Њ–±–µ–љ–љ–Њ –≤–∞–ґ–љ–Њ –і–ї—П –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А–Њ–≤ —А–µ–∞–ї—М–љ–Њ–≥–Њ –≤—А–µ–Љ–µ–љ–Є, –≥–і–µ –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ –њ–Њ–ї—Г—З–∞—В—М —А–µ–Ј—Г–ї—М—В–∞—В —Б—А–∞–Ј—Г, –±–µ–Ј —Б—Г—Й–µ—Б—В–≤–µ–љ–љ—Л—Е –Ј–∞–і–µ—А–ґ–µ–Ї. –Ф–ї—П –Љ–љ–Њ–≥–Њ–њ—А–Њ—Ж–µ—Б—Б–Њ—А–љ—Л—Е –≤—Л—З–Є—Б–ї–Є—В–µ–ї—М–љ—Л—Е —Б–Є—Б—В–µ–Љ –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ —Б–Њ–Ј–і–∞–≤–∞—В—М —Б–њ–µ—Ж–Є–∞–ї—М–љ—Л–µ –њ—А–Њ–≥—А–∞–Љ–Љ—Л. –Т —В–µ–Ї—Б—В–µ —В–∞–Ї–Њ–є –њ—А–Њ–≥—А–∞–Љ–Љ—Л –Њ–њ—А–µ–і–µ–ї—П—О—В—Б—П —З–∞—Б—В–Є (–≤–µ—В–Ї–Є), –Ї–Њ—В–Њ—А—Л–µ –Љ–Њ–≥—Г—В –≤—Л–њ–Њ–ї–љ—П—В—Б—П –њ–∞—А–∞–ї–ї–µ–ї—М–љ–Њ, –∞ —В–∞–Ї–ґ–µ –∞–ї–≥–Њ—А–Є—В–Љ –Є—Е –≤–Ј–∞–Є–Љ–Њ–і–µ–є—Б—В–≤–Є—П. –¶–µ–ї—М—О –і–∞–љ–љ–Њ–є —А–∞–±–Њ—В—Л —П–≤–ї—П–µ—В—Б—П –њ–Њ—Б—В—А–Њ–µ–љ–Є–µ –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А–∞ –і–ї—П —Н—Д—Д–µ–Ї—В–Є–≤–љ–Њ–≥–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П –љ–∞ –Љ–љ–Њ–≥–Њ–њ—А–Њ—Ж–µ—Б—Б–Њ—А–љ—Л—Е –≤—Л—З–Є—Б–ї–Є—В–µ–ї—М–љ—Л—Е —Б–Є—Б—В–µ–Љ–∞—Е.
2 –Я–Њ—Б—В–∞–љ–Њ–≤–Ї–∞ –Ј–∞–і–∞—З–Є
–Ч–∞–і–∞—З–∞, –Ї–Њ—В–Њ—А—Г—О –Љ—Л –±—Г–і–µ–Љ —А–∞—Б—Б–Љ–∞—В—А–Є–≤–∞—В—М –≤ –і–∞–љ–љ–Њ–є —Б—В–∞—В—М–µ, —Н—В–Њ –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—Ж–Є—П –±–Є–љ–∞—А–љ—Л—Е –Њ–±—А–∞–Ј–Њ–≤ (—З–µ—А–љ–Њ-–±–µ–ї—Л—Е –≤–Є–і–µ–Њ–Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–є).
–Я–Њ—Б—В–∞–љ–Њ–≤–Ї—Г –Ј–∞–і–∞—З–Є –Љ–Њ–ґ–љ–Њ —Б—Д–Њ—А–Љ—Г–ї–Є—А–Њ–≤–∞—В—М —В–∞–Ї : —А–∞–Ј—А–∞–±–Њ—В–∞—В—М –њ–∞—А–∞–ї–ї–µ–ї—М–љ—Г—О –њ—А–Њ–≥—А–∞–Љ–Љ—Г –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—Ж–Є–Є –±–Є–љ–∞—А–љ—Л—Е –Њ–±—А–∞–Ј–Њ–≤, —Б–њ–Њ—Б–Њ–±–љ—Г—О –Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ–Њ –Њ–±—А–∞–±–∞—В—Л–≤–∞—В—М –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –Њ–±—А–∞–Ј–Њ–≤.
3 –†–µ—И–µ–љ–Є–µ
–Ф–ї—П —А–µ–∞–ї–Є–Ј–∞—Ж–Є–Є –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А–∞ –±—Г–і–µ–Љ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –Љ–Њ–і–µ–ї–Є –Є—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ—Л—Е –љ–µ–є—А–Њ–љ–љ—Л—Е —Б–µ—В–µ–є.
3.1 –Ш—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ–∞—П –љ–µ–є—А–Њ–љ–љ–∞—П —Б–µ—В—М
–Ш—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ–∞—П –љ–µ–є—А–Њ–љ–љ–∞—П —Б–µ—В—М —Н—В–Њ —Б–Њ–≤–Њ–Ї—Г–њ–љ–Њ—Б—В—М –љ–µ–є—А–Њ–љ–љ—Л—Е —Н–ї–µ–Љ–µ–љ—В–Њ–≤ (—А–Є—Б. 1) –Є —Б–≤—П–Ј–µ–є –Љ–µ–ґ–і—Г –љ–Є–Љ–Є [3].
![\includegraphics[width=10cm]{pict/Image39.ps}](content/parallel-mcs-classifier.html/img1.gif)
- –Э–µ–є—А–Њ–љ–љ—Л–є —Н–ї–µ–Љ–µ–љ—В (–љ–µ–є—А–Њ–љ) –Њ–±–ї–∞–і–∞–µ—В –≥—А—Г–њ–њ–Њ–є
–Њ–і–љ–Њ–љ–∞–њ—А–∞–≤–ї–µ–љ–љ—Л—Е –≤—Е–Њ–і–љ—Л—Е —Б–≤—П–Ј–µ–є
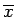 ,
—Б–Њ–µ–і–Є–љ–µ–љ–љ—Л—Е —Б –≤—Л—Е–Њ–і–∞–Љ–Є –і—А—Г–≥–Є—Е –љ–µ–є—А–Њ–љ–Њ–≤. –Ъ–∞–ґ–і—Л–є –≤—Е–Њ–і
,
—Б–Њ–µ–і–Є–љ–µ–љ–љ—Л—Е —Б –≤—Л—Е–Њ–і–∞–Љ–Є –і—А—Г–≥–Є—Е –љ–µ–є—А–Њ–љ–Њ–≤. –Ъ–∞–ґ–і—Л–є –≤—Е–Њ–і 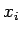 —Е–∞—А–∞–Ї—В–µ—А–Є–Ј—Г–µ—В—Б—П –≤–µ–ї–Є—З–Є–љ–Њ–є —Б–Є–љ–∞–њ—В–Є—З–µ—Б–Ї–Њ–є —Б–≤—П–Ј–Є –Є–ї–Є –≤–µ—Б–Њ–Љ
—Е–∞—А–∞–Ї—В–µ—А–Є–Ј—Г–µ—В—Б—П –≤–µ–ї–Є—З–Є–љ–Њ–є —Б–Є–љ–∞–њ—В–Є—З–µ—Б–Ї–Њ–є —Б–≤—П–Ј–Є –Є–ї–Є –≤–µ—Б–Њ–Љ 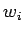 .
.
- –Ъ–∞–ґ–і—Л–є –љ–µ–є—А–Њ–љ –Є–Љ–µ–µ—В —В–µ–Ї—Г—Й–µ–µ —Б–Њ—Б—В–Њ—П–љ–Є–µ, –Њ–њ—А–µ–і–µ–ї—П–µ–Љ–Њ–µ, –Ї–∞–Ї
–≤–Ј–≤–µ—И–µ–љ–љ–∞—П —Б—Г–Љ–Љ–∞ –µ–≥–Њ –≤—Е–Њ–і–Њ–≤1
:
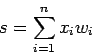
- –Э–µ–є—А–Њ–љ –Є–Љ–µ–µ—В –≤—Л—Е–Њ–і–љ—Г—О —Б–≤—П–Ј—М
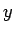 , —Б –Ї–Њ—В–Њ—А–Њ–є —Б–Є–≥–љ–∞–ї
–њ–Њ—Б—В—Г–њ–∞–µ—В –љ–∞ –≤—Е–Њ–і—Л —Б–ї–µ–і—Г—О—Й–Є—Е –љ–µ–є—А–Њ–љ–Њ–≤. –Т—Л—Е–Њ–і –љ–µ–є—А–Њ–љ–∞ –µ—Б—В—М —Д—Г–љ–Ї—Ж–Є—П –µ–≥–Њ
—Б–Њ—Б—В–Њ—П–љ–Є—П:
, —Б –Ї–Њ—В–Њ—А–Њ–є —Б–Є–≥–љ–∞–ї
–њ–Њ—Б—В—Г–њ–∞–µ—В –љ–∞ –≤—Е–Њ–і—Л —Б–ї–µ–і—Г—О—Й–Є—Е –љ–µ–є—А–Њ–љ–Њ–≤. –Т—Л—Е–Њ–і –љ–µ–є—А–Њ–љ–∞ –µ—Б—В—М —Д—Г–љ–Ї—Ж–Є—П –µ–≥–Њ
—Б–Њ—Б—В–Њ—П–љ–Є—П:
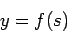
–§—Г–љ–Ї—Ж–Є—П –љ–∞–Ј—Л–≤–∞–µ—В—Б—П –∞–Ї—В–Є–≤–∞—Ж–Є–Њ–љ–љ–Њ–є.
–љ–∞–Ј—Л–≤–∞–µ—В—Б—П –∞–Ї—В–Є–≤–∞—Ж–Є–Њ–љ–љ–Њ–є.
–Ь–љ–Њ–ґ–µ—Б—В–≤–Њ –≤—Б–µ—Е –љ–µ–є—А–Њ–љ–Њ–≤ –љ–µ–є—А–Њ–љ–љ–Њ–є —Б–µ—В–Є –Љ–Њ–ґ–љ–Њ —А–∞–Ј–і–µ–ї–Є—В—М –љ–∞ –њ–Њ–і–Љ–љ–Њ–ґ–µ—Б—В–≤–∞ - —В.–љ. —Б–ї–Њ–Є. –°–ї–Њ–є –Є—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ–Њ–є –љ–µ–є—А–Њ–љ–љ–Њ–є —Б–µ—В–Є —Н—В–Њ –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ –љ–µ–є—А–Њ–љ–Њ–≤ –љ–∞ –Ї–Њ—В–Њ—А—Л–µ –≤ –Ї–∞–ґ–і—Л–є —В–∞–Ї—В –≤—А–µ–Љ–µ–љ–Є –њ–∞—А–∞–ї–ї–µ–ї—М–љ–Њ –њ–Њ—Б—В—Г–њ–∞—О—В —Б–Є–≥–љ–∞–ї—Л –Њ—В –і—А—Г–≥–Є—Е –љ–µ–є—А–Њ–љ–Њ–≤ –і–∞–љ–љ–Њ–є —Б–µ—В–Є [3]. –Т–Ј–∞–Є–Љ–Њ–і–µ–є—Б—В–≤–Є–µ –љ–µ–є—А–Њ–љ–Њ–≤ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В –њ–Њ—Б–ї–Њ–є–љ–Њ.
3.2 –Ъ–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А
–Т –і–∞–љ–љ–Њ–є —А–∞–±–Њ—В–µ –і–ї—П —А–µ–∞–ї–Є–Ј–∞—Ж–Є–Є –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А–∞ –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –Њ–і–љ–Њ—Б–ї–Њ–є–љ–∞—П –љ–µ–є—А–Њ–љ–љ–∞—П —Б–µ—В—М (–њ–µ—А—Б–µ–њ—В—А–Њ–љ) –Є–Ј 10 –љ–µ–є—А–Њ–љ–Њ–≤ (—А–Є—Б. 2).
3.2.1 –Я–∞—А–∞–Љ–µ—В—А—Л —Б–µ—В–Є
![\includegraphics[width=12cm]{pict/Image44.ps}](content/parallel-mcs-classifier.html/img9.gif)
- –Њ–і–љ–Њ—Б–ї–Њ–є–љ–∞—П –љ–µ–є—А–Њ–љ–љ–∞—П —Б–µ—В—М (—А–Є—Б. 2)
- 35 –≤—Е–Њ–і–Њ–≤
- 10 –≤—Л—Е–Њ–і–Њ–≤
- —Б–Њ—Б—В–Њ—П–љ–Є–µ –љ–µ–є—А–Њ–љ–∞
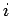 :
:
- –њ–Њ—А–Њ–≥–Њ–≤–∞—П —Д—Г–љ–Ї—Ж–Є—П –∞–Ї—В–Є–≤–∞—Ж–Є–Є —Б –њ–Њ—А–Њ–≥–Њ–Љ
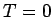
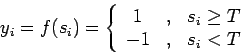
(2)
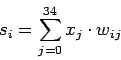
3.2.2 –Р–ї–≥–Њ—А–Є—В–Љ —А–∞–±–Њ—В—Л –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А–∞
–Э–∞ –≤—Е–Њ–і –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А–∞ –њ–Њ–і–∞—О—В—Б—П –±–Є–љ–∞—А–љ—Л–µ –Ї–∞—А—В–Є–љ–Ї–Є (—А–Є—Б. 3) —А–∞–Ј–Љ–µ—А–Њ–Љ ![]() —В–Њ—З–µ–Ї —Б
–Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–µ–Љ —Ж–Є—Д—А (
—В–Њ—З–µ–Ї —Б
–Є–Ј–Њ–±—А–∞–ґ–µ–љ–Є–µ–Љ —Ж–Є—Д—А (![]() ), —В.–µ. –≤—Б–µ–≥–Њ
), —В.–µ. –≤—Б–µ–≥–Њ ![]() –≤—Е–Њ–і–Њ–≤. –Э–∞ –≤—Л—Е–Њ–і–µ –њ–Њ–ї—Г—З–∞–µ–Љ —Б–ї–Њ–≤–Њ
–≤—Е–Њ–і–Њ–≤. –Э–∞ –≤—Л—Е–Њ–і–µ –њ–Њ–ї—Г—З–∞–µ–Љ —Б–ї–Њ–≤–Њ ![]() ,
, ![]() , —В.–µ. –≤—Б–µ–≥–Њ 10 –≤—Л—Е–Њ–і–Њ–≤. –Э–Њ–Љ–µ—А
, —В.–µ. –≤—Б–µ–≥–Њ 10 –≤—Л—Е–Њ–і–Њ–≤. –Э–Њ–Љ–µ—А ![]() , –і–ї—П –Ї–Њ—В–Њ—А–Њ–≥–Њ –≤—Л—Е–Њ–і
, –і–ї—П –Ї–Њ—В–Њ—А–Њ–≥–Њ –≤—Л—Е–Њ–і ![]() ,
—Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –љ–Њ–Љ–µ—А—Г –Ї–ї–∞—Б—Б–∞ –≤—Е–Њ–і–љ–Њ–≥–Њ –Њ–±—А–∞–Ј—Ж–∞.
,
—Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г–µ—В –љ–Њ–Љ–µ—А—Г –Ї–ї–∞—Б—Б–∞ –≤—Е–Њ–і–љ–Њ–≥–Њ –Њ–±—А–∞–Ј—Ж–∞.

–Т–∞–ґ–љ–Њ–є –Њ—Б–Њ–±–µ–љ–љ–Њ—Б—В—М—О –Є—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ–Њ–є –љ–µ–є—А–Њ–љ–љ–Њ–є —Б–µ—В–Є –µ—Б—В—М –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М –µ—С –Њ–±—Г—З–µ–љ–Є—П. –Я—А–Њ—Ж–µ—Б—Б –Њ–±—Г—З–µ–љ–Є—П —Б–≤–Њ–і–Є—В—Б—П –Ї –њ—А–Њ—Ж–µ–і—Г—А–µ –Ї–Њ—А—А–µ–Ї—В–Є—А–Њ–≤–Ї–Є –≤–µ—Б–Њ–≤—Л—Е –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В–Њ–≤. –Т –Ї–∞—З–µ—Б—В–≤–µ –Љ–µ—В–Њ–і–∞ –Њ–±—Г—З–µ–љ–Є—П –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П –њ—А–∞–≤–Є–ї–Њ –Т–Є–і—А–Њ—Г-–•–Њ—Д—Д–∞ [4]:
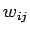 - –≤–µ—Б–Њ–≤–Њ–є –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В —Б–≤—П–Ј–Є -—В–Њ–≥–Њ –љ–µ–є—А–Њ–љ–∞ —Б
- –≤–µ—Б–Њ–≤–Њ–є –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В —Б–≤—П–Ј–Є -—В–Њ–≥–Њ –љ–µ–є—А–Њ–љ–∞ —Б 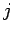 -—В—Л–Љ –≤—Е–Њ–і–Њ–Љ
-—В—Л–Љ –≤—Е–Њ–і–Њ–Љ 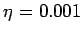 - –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В —Б–Ї–Њ—А–Њ—Б—В–Є –Њ–±—Г—З–µ–љ–Є—П
- –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В —Б–Ї–Њ—А–Њ—Б—В–Є –Њ–±—Г—З–µ–љ–Є—П 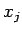 - -—В—Л–є –≤—Е–Њ–і —Б–µ—В–Є
- -—В—Л–є –≤—Е–Њ–і —Б–µ—В–Є 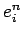 - –Њ—И–Є–±–Ї–∞ –љ–µ–є—А–Њ–љ–∞ –љ–∞
- –Њ—И–Є–±–Ї–∞ –љ–µ–є—А–Њ–љ–∞ –љ–∞ 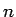 -—В–Њ–Љ –Њ–±—А–∞–Ј—Ж–µ
-—В–Њ–Љ –Њ–±—А–∞–Ј—Ж–µ
–≥–і–µ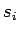 - —Б–Њ—Б—В–Њ—П–љ–Є–µ (1)
–љ–µ–є—А–Њ–љ–∞
- —Б–Њ—Б—В–Њ—П–љ–Є–µ (1)
–љ–µ–є—А–Њ–љ–∞ 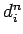 - –≤–µ—А–љ—Л–є –≤—Л—Е–Њ–і –љ–µ–є—А–Њ–љ–∞ –љ–∞ -—В–Њ–Љ –Њ–±—А–∞–Ј—Ж–µ
- –≤–µ—А–љ—Л–є –≤—Л—Е–Њ–і –љ–µ–є—А–Њ–љ–∞ –љ–∞ -—В–Њ–Љ –Њ–±—А–∞–Ј—Ж–µ
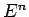 - –Њ—И–Є–±–Ї–∞ —Б–µ—В–Є –љ–∞ -—В–Њ–Љ
–Њ–±—А–∞–Ј—Ж–µ
- –Њ—И–Є–±–Ї–∞ —Б–µ—В–Є –љ–∞ -—В–Њ–Љ
–Њ–±—А–∞–Ј—Ж–µ
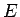 - –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–∞—П –Њ—И–Є–±–Ї–∞ —Б–µ—В–Є
- –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–∞—П –Њ—И–Є–±–Ї–∞ —Б–µ—В–Є
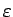
 - –і–Њ–њ—Г—Б—В–Є–Љ–∞—П –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–∞—П –Њ—И–Є–±–Ї–∞ —Б–µ—В–Є
- –і–Њ–њ—Г—Б—В–Є–Љ–∞—П –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–∞—П –Њ—И–Є–±–Ї–∞ —Б–µ—В–Є
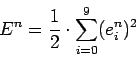
–Ґ–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ, –њ—А–µ–ґ–і–µ —З–µ–Љ –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А –љ–∞—З–љ–µ—В —А–∞–±–Њ—В–∞—В—М –µ–≥–Њ –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ –Њ–±—Г—З–Є—В—М –љ–∞ –Љ–љ–Њ–ґ–µ—Б—В–≤–µ —Г—З–µ–±–љ—Л—Е –њ—А–Є–Љ–µ—А–Њ–≤, –Ї–Њ—В–Њ—А–Њ–µ –њ—А–µ–і—Б—В–∞–≤–ї—П–µ—В —Б–Њ–±–Њ–є –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ –њ–∞—А - (–Ї–∞—А—В–Є–љ–Ї–∞, –≤—Л—Е–Њ–і —Б–µ—В–Є).
–¶–Є–Ї–ї –Њ–±—Г—З–µ–љ–Є—П –≤—Л–≥–ї—П–і–Є—В —В–∞–Ї :
- –њ—А–Њ–≥–љ–∞—В—М —З–µ—А–µ–Ј —Б–µ—В—М –≤—Б–µ –Њ–±—А–∞–Ј—Ж—Л –Є–Ј –Љ–љ–Њ–ґ–µ—Б—В–≤–∞ —Г—З–µ–±–љ—Л—Е
–њ—А–Є–Љ–µ—А–Њ–≤ –Є —А–∞—Б—Б—З–Є—В–∞—В—М –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ—Г—О –Њ—И–Є–±–Ї—Г —Б–µ—В–Є –њ–Њ (6)
- –µ—Б–ї–Є
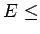 —В–Њ –Ї–Њ–љ–µ—Ж
—В–Њ –Ї–Њ–љ–µ—Ж
- –≤ —Б–ї—Г—З–∞–є–љ–Њ–Љ –њ–Њ—А—П–і–Ї–µ –њ–Њ–і–∞—В—М –љ–∞ –≤—Е–Њ–і —Б–µ—В–Є –≤—Б–µ –Њ–±—А–∞–Ј—Ж—Л –Є–Ј
–Љ–љ–Њ–ґ–µ—Б—В–≤–∞ —Г—З–µ–±–љ—Л—Е –њ—А–Є–Љ–µ—А–Њ–≤, –і–ї—П –Ї–∞–ґ–і–Њ–≥–Њ –Њ–±—А–∞–Ј—Ж–∞ –Є –≤—Л—Е–Њ–і–∞ —Б–µ—В–Є
—А–∞—Б—Б—З–Є—В–∞—В—М –Њ—И–Є–±–Ї—Г –њ–Њ (4) –Є
—Б–Ї–Њ—А—А–µ–Ї—В–Є—А–Њ–≤–∞—В—М –≤–µ—Б–∞ –њ–Њ (3)
- –њ–µ—А–µ–є—В–Є –љ–∞ –њ.1
3.3 –†–µ–∞–ї–Є–Ј–∞—Ж–Є—П —Б —А–∞—Б–њ–∞—А–∞–ї–ї–µ–ї–Є–≤–∞–љ–Є–µ–Љ
–°–Њ–Њ—В–≤–µ—В—Б—В–≤–µ–љ–љ–Њ –њ—А–µ–і—Б—В–∞–≤–ї–µ–љ–љ–Њ–є –≤—Л—И–µ –Љ–Њ–і–µ–ї–Є, –љ–∞ —П–Ј—Л–Ї–µ MC# [5][6][7] –љ–∞–њ–Є—Б–∞–љ –њ–∞—А–∞–ї–ї–µ–ї—М–љ—Л–є –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А –±–Є–љ–∞—А–љ—Л—Е –Њ–±—А–∞–Ј–Њ–≤.
''–Я–∞–Љ—П—В—М'' —Б–µ—В–Є —Н—В–Њ –Љ–∞—В—А–Є—Ж–∞ –≤–µ—Б–Њ–≤—Л—Е –Ї–Њ—Н—Д—Д–Є—Ж–Є–µ–љ—В–Њ–≤ ![]() . –Э–∞
—Н—В–∞–њ–µ –Є–љ–Є—Ж–Є–∞–ї–Є–Ј–∞—Ж–Є–Є –њ—А–Њ–≥—А–∞–Љ–Љ—Л –њ–Њ—А–Њ–ґ–і–∞–µ—В—Б—П –љ–∞—З–∞–ї—М–љ–∞—П —Б–µ—В—М. –≠—В–∞ —Б–µ—В—М
–Њ–±—Г—З–∞–µ—В—Б—П –љ–∞ –Љ–љ–Њ–ґ–µ—Б—В–≤–µ –њ–∞—А [–Њ–±—А–∞–Ј,–≤—Л—Е–Њ–і_—Б–µ—В–Є], –Ї–Њ—В–Њ—А—Л–µ
—Б–Њ–і–µ—А–ґ–∞—В—Б—П –≤ –і–≤—Г—Е —В–µ–Ї—Б—В–Њ–≤—Л—Е —Д–∞–є–ї–∞—Е : patterns.dat - –Њ–±—Г—З–∞—О—Й–∞—П –≤—Л–±–Њ—А–Ї–∞,
targets.dat - –≤–µ—А–љ—Л–µ –≤—Л—Е–Њ–і—Л –і–ї—П –Њ–±—Г—З–∞—О—Й–µ–є –≤—Л–±–Њ—А–Ї–Є. –°–Њ–Ј–і–∞–µ—В—Б—П —А–∞–±–Њ—З–∞—П
–Љ–∞—В—А–Є—Ж–∞ –≤–µ—Б–Њ–≤, —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–∞—П [patterns.dat, targets.dat], –Ї–Њ—В–Њ—А–∞—П
–Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П, –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Є —Б–Њ–Ј–і–∞–≤–∞–µ–Љ—Л–Љ–Є, –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А–∞–Љ–Є –і–ї—П
–Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ–Њ–≥–Њ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –Њ–±—А–∞–Ј–Њ–≤ –Є–Ј —Д–∞–є–ї–∞ tests.dat –Ґ–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ,
–њ–Њ–ї—Г—З–µ–љ–љ–∞—П —Б–Є—Б—В–µ–Љ–∞ –Љ–Њ–ґ–µ—В ''—З–Є—В–∞—В—М'' —Б–ї–Њ–≤–∞–Љ–Є.
. –Э–∞
—Н—В–∞–њ–µ –Є–љ–Є—Ж–Є–∞–ї–Є–Ј–∞—Ж–Є–Є –њ—А–Њ–≥—А–∞–Љ–Љ—Л –њ–Њ—А–Њ–ґ–і–∞–µ—В—Б—П –љ–∞—З–∞–ї—М–љ–∞—П —Б–µ—В—М. –≠—В–∞ —Б–µ—В—М
–Њ–±—Г—З–∞–µ—В—Б—П –љ–∞ –Љ–љ–Њ–ґ–µ—Б—В–≤–µ –њ–∞—А [–Њ–±—А–∞–Ј,–≤—Л—Е–Њ–і_—Б–µ—В–Є], –Ї–Њ—В–Њ—А—Л–µ
—Б–Њ–і–µ—А–ґ–∞—В—Б—П –≤ –і–≤—Г—Е —В–µ–Ї—Б—В–Њ–≤—Л—Е —Д–∞–є–ї–∞—Е : patterns.dat - –Њ–±—Г—З–∞—О—Й–∞—П –≤—Л–±–Њ—А–Ї–∞,
targets.dat - –≤–µ—А–љ—Л–µ –≤—Л—Е–Њ–і—Л –і–ї—П –Њ–±—Г—З–∞—О—Й–µ–є –≤—Л–±–Њ—А–Ї–Є. –°–Њ–Ј–і–∞–µ—В—Б—П —А–∞–±–Њ—З–∞—П
–Љ–∞—В—А–Є—Ж–∞ –≤–µ—Б–Њ–≤, —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й–∞—П [patterns.dat, targets.dat], –Ї–Њ—В–Њ—А–∞—П
–Є—Б–њ–Њ–ї—М–Ј—Г–µ—В—Б—П, –і–Є–љ–∞–Љ–Є—З–µ—Б–Ї–Є —Б–Њ–Ј–і–∞–≤–∞–µ–Љ—Л–Љ–Є, –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А–∞–Љ–Є –і–ї—П
–Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ–Њ–≥–Њ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є—П –Њ–±—А–∞–Ј–Њ–≤ –Є–Ј —Д–∞–є–ї–∞ tests.dat –Ґ–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ,
–њ–Њ–ї—Г—З–µ–љ–љ–∞—П —Б–Є—Б—В–µ–Љ–∞ –Љ–Њ–ґ–µ—В ''—З–Є—В–∞—В—М'' —Б–ї–Њ–≤–∞–Љ–Є.
–Ъ–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А —А–µ–∞–ї–Є–Ј—Г–µ—В—Б—П —В—А–µ–Љ—П –Ї–ї–∞—Б—Б–∞–Љ–Є :
// –Њ–і–љ–Њ—Б–ї–Њ–є–љ–∞—П —Б–µ—В—М
class OneLayerNet { . . . }
// –њ–µ—А—Б–µ–њ—В—А–Њ–љ, –њ–Њ—А–Њ–≥–Њ–≤–∞—П —Д—Г–љ–Ї—Ж–Є—П –∞–Ї—В–Є–≤–∞—Ж–Є–Є
class Perceptron : OneLayerNet { . . . }
// –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А, 35 –≤—Е–Њ–і–Њ–≤, 10 –≤—Л—Е–Њ–і–Њ–≤
// —А–∞—Б–њ–Њ–Ј–љ–∞–µ—В –±–Є–љ–∞—А–љ—Л–µ –Ї–∞—А—В–Є–љ–Ї–Є 5x7 —В–Њ—З–µ–Ї
class Classificator : Perceptron { . . . }
ParClassificator - –Ї–ї–∞—Б—Б, —А–µ–∞–ї–Є–Ј—Г—О—Й–Є–є –њ–∞—А–∞–ї–ї–µ–ї—М–љ—Л–є –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А. –Э–∞ —Н—В–∞–њ–µ –Є–љ–Є—Ж–Є–∞–ї–Є–Ј–∞—Ж–Є–Є –њ—А–Њ–≥—А–∞–Љ–Љ—Л –њ—А–Є –њ–Њ–Љ–Њ—Й–Є –Ї–Њ–љ—Б—В—А—Г–Ї—В–Њ—А–∞ ParClassificator(), –љ–∞ –Њ—Б–љ–Њ–≤–µ —Б–Њ–і–µ—А–ґ–Є–Љ–Њ–≥–Њ patterns.dat –Є targets.dat, —Б–Њ–Ј–і–∞–µ—В—Б—П —А–∞–±–Њ—З–∞—П –Љ–∞—В—А–Є—Ж–∞ –≤–µ—Б–Њ–≤ m_weight. –°–Њ–±—Б—В–≤–µ–љ–љ–Њ, –Љ–µ—Е–∞–љ–Є–Ј–Љ —А–∞—Б–њ–∞—А–∞–ї–ї–µ–ї–Є–≤–∞–љ–Є—П –Ј–∞–Ї–ї—О—З–µ–љ –≤ –і–≤—Г—Е –Љ–µ—В–Њ–і–∞—Е recognize –Є Get :
- movable recognize(double[,] W, sbyte[] I, Channel(NeuralIO)c)
—Н—В–Њ –њ–µ—А–µ–Љ–µ—Й–∞–µ–Љ—Л–є (—В.–µ. –≤—Л–њ–Њ–ї–љ—П–µ–Љ—Л–є –њ–∞—А–∞–ї–ї–µ–ї—М–љ–Њ —Б –Њ—Б—В–∞–ї—М–љ–Њ–є –њ—А–Њ–≥—А–∞–Љ–Љ–Њ–є)
–Љ–µ—В–Њ–і, –Ї–Њ—В–Њ—А—Л–є —А–∞—Б–њ–Њ–Ј–љ–∞–µ—В –±–Є–љ–∞—А–љ—Л–є –Њ–±—А–∞–Ј I, –Є—Б–њ–Њ–ї—М–Ј—Г—П
–Љ–∞—В—А–Є—Ж—Г –≤–µ—Б–Њ–≤ W. –†–µ–Ј—Г–ї—М—В–∞—В –њ–Њ–Љ–µ—Й–∞–µ—В—Б—П –≤ —В.–љ. –Ї–∞–љ–∞–ї c.
–Ъ–Њ–љ—Б—В—А—Г–Ї—Ж–Є—П c(res) –≤ –љ–µ–Ї–Њ—В–Њ—А–Њ–Љ —Б–Љ—Л—Б–ї–µ –∞–љ–∞–ї–Њ–≥ –Ї–Њ–љ—Б—В—А—Г–Ї—Ж–Є–Є return(res)
–і–ї—П –Њ–±—Л—З–љ—Л—Е ( –њ–Њ—Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М–љ—Л—Е ) —Д—Г–љ–Ї—Ж–Є–є.
- void Get() & Channel m_channel( NeuralIO n )
–°—В–∞–љ–і–∞—А—В–љ–∞—П –Ї–Њ–љ—Б—В—А—Г–Ї—Ж–Є—П —П–Ј—Л–Ї–∞ MC#. –Ч–і–µ—Б—М –Њ–±—К—П–≤–ї—П–µ—В—Б—П –Ї–∞–љ–∞–ї m_channel —В–Є–њ–∞ NeuralIO –Є –Љ–µ—В–Њ–і-–Њ–±—А–∞–±–Њ—В—З–Є–Ї –Ї–∞–љ–∞–ї–∞ Get, –Ї–Њ—В–Њ—А—Л–є –Ј–∞–±–Є—А–∞–µ—В –Є–Ј –Ї–∞–љ–∞–ї–∞ –і–∞–љ–љ—Л–µ, –њ–Њ—Б–ї–∞–љ–љ—Л–µ —В—Г–і–∞, –њ–∞—А–∞–ї–ї–µ–ї—М–љ–Њ —А–∞–±–Њ—В–∞—О—Й–Є–Љ–Є –Љ–µ—В–Њ–і–∞–Љ–Є recognize.
–Я–∞—А–∞–ї–ї–µ–ї—М–љ—Л–є –Ї–ї–∞—Б—Б–Є—Д–Є–Ї–∞—В–Њ—А ParClassificator –Њ—Б—Г—Й–µ—Б—В–≤–ї—П–µ—В –Њ–і–љ–Њ–≤—А–µ–Љ–µ–љ–љ–Њ–µ —А–∞—Б–њ–Њ–Ј–љ–∞–≤–∞–љ–Є–µ –±–Є–љ–∞—А–љ—Л—Е –Њ–±—А–∞–Ј–Њ–≤ –Є–Ј tests.dat –њ—А–Є –њ–Њ–Љ–Њ—Й–Є –Љ–µ—В–Њ–і–∞ makeTestPar. –≠—В–Њ—В –Љ–µ—В–Њ–і –і–ї—П –Ї–∞–ґ–і–Њ–≥–Њ –Њ–±—А–∞–Ј–∞ –Є–Ј tests.dat –≤—Л–Ј—Л–≤–∞–µ—В movable –Љ–µ—В–Њ–і recognize –Є —Б–Њ–±–Є—А–∞–µ—В —А–µ–Ј—Г–ї—М—В–∞—В—Л –Љ–µ—В–Њ–і–Њ–Љ Get.
class ParClassificator {
. . .
protected double[,] m_weight;
public ParClassificator() {
Classificator nnet=new Classificator(N);
nnet.teach("patterns.dat","targets.dat");
m_weight=nnet.weight();
. . .
}
. . .
public void makeTestPar(string file) {
. . .
for(i=0;(loadPattern()==1);i++) {
recognize(m_weight,Copy(m_pattern), m_channel );
}
for(int j=0;j<i;j++) { Get(); }
. . .
}
public movable recognize(double [,] W, sbyte[] I, Channel( NeuralIO ) c ) {
Classificator nnet=new Classificator(N);
NeuralIO n=new NeuralIO(IN_SIZE,OUT_SIZE);
n.I(I);
nnet.I(I);
nnet.weight(W);
nnet.step();
n.O(nnet.O());
c(n);
}
public void Get() & Channel m_channel( NeuralIO n ) {
printIn(n.I());
printOut(n.O());
}
}
4 –†–µ–Ј—Г–ї—М—В–∞—В
–Ф–∞–љ–љ–∞—П –њ—А–Њ–≥—А–∞–Љ–Љ–∞ —А–µ–∞–ї–Є–Ј—Г–µ—В –Љ–Њ–і–µ–ї—М —А–∞—Б–њ–∞—А–∞–ї–ї–µ–ї–Є–≤–∞–љ–Є—П –њ–Њ –і–∞–љ–љ—Л–Љ - –≤—Б–µ –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ –і–∞–љ–љ—Л—Е –і–ї—П –Њ–±—А–∞–±–Њ—В–Ї–Є –і–µ–ї–Є—В—Б—П –љ–∞ —З–∞—Б—В–Є –Є —А–∞—Б–њ—А–µ–і–µ–ї—П–µ—В—Б—П –Љ–µ–ґ–і—Г –≤—Л—З–Є—Б–ї–Є—В–µ–ї—М–љ—Л–Љ–Є —Г–Ј–ї–∞–Љ–Є, –Ї–Њ—В–Њ—А—Л–µ –љ–µ–Ј–∞–≤–Є—Б–Є–Љ–Њ –і—А—Г–≥ –Њ—В –і—А—Г–≥–∞ –њ–Њ –µ–і–Є–љ–Њ–Љ—Г –∞–ї–≥–Њ—А–Є—В–Љ—Г –Њ–±—А–∞–±–∞—В—Л–≤–∞—О—В —Б–≤–Њ–Є —З–∞—Б—В–Є.
–Я—А–Є —Г–≤–µ–ї–Є—З–µ–љ–Є–Є –Ї–Њ–ї–Є—З–µ—Б—В–≤–∞ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–Њ–≤, –њ—А–µ–і–њ–Њ–ї–∞–≥–∞–µ—В—Б—П —Г—Б–Ї–Њ—А–µ–љ–Є–µ
–±–ї–Є–Ј–Ї–Њ–µ –Ї –ї–Є–љ–µ–є–љ–Њ–Љ—Г. –£—Б–Ї–Њ—А–µ–љ–Є–µ[8] –љ–∞ ![]() –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞—Е —Н—В–Њ –Њ—В–љ–Њ—И–µ–љ–Є–µ
–њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞—Е —Н—В–Њ –Њ—В–љ–Њ—И–µ–љ–Є–µ
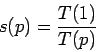
–≥–і–µ

–Ґ–µ–Ї—Б—В –њ—А–Њ–≥—А–∞–Љ–Љ—Л –љ–∞ MC# [ –Ј–і–µ—Б—М ]
–Ы–Є—В–µ—А–∞—В—Г—А–∞
-
- 1
- –С–Њ—А–Є—Б–Њ–≤ –Х.–°. –Ш—Б–Ї—Г—Б—Б—В–≤–µ–љ–љ—Л–µ –љ–µ–є—А–Њ–љ–љ—Л–µ —Б–µ—В–Є - http://www.mechanoid.kiev.ua
- 2
- –С–Њ—А–Є—Б–Њ–≤ –Х.–°. –Т—Л—З–Є—Б–ї–Є—В–µ–ї—М–љ—Л–µ —Б–Є—Б—В–µ–Љ—Л —Б–≤–µ—А—Е–≤—Л—Б–Њ–Ї–Њ–є –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є. - http://www.mechanoid.kiev.ua/parallel-high-performance-computing.html
- 3
- –У–Њ–ї–Њ–≤–Ї–Њ –Т.–Р., –њ–Њ–і —А–µ–і. –У–∞–ї—Г—И–Ї–Є–љ–∞ –Р.–Ш. –Э–µ–є—А–Њ–љ–љ—Л–µ —Б–µ—В–Є: –Њ–±—Г—З–µ–љ–Є–µ, –Њ—А–≥–∞–љ–Є–Ј–∞—Ж–Є—П –Є –њ—А–Є–Љ–µ–љ–µ–љ–Є–µ. - –Ь–Њ—Б–Ї–≤–∞ : –Ш–Я–†–Ц–†, 2001. - 256 c.
- 4
- –£–Њ—Б—Б–µ—А–Љ–µ–љ –§. –Э–µ–є—А–Њ–Ї–Њ–Љ–њ—М—О—В–µ—А–љ–∞—П —В–µ—Е–љ–Є–Ї–∞ : –Ґ–µ–Њ—А–Є—П –Є –њ—А–∞–Ї—В–Є–Ї–∞. - –Ь–Њ—Б–Ї–≤–∞ : –Ь–Є—А, 1992. - 200 c.
- 5
- MC# - http://www.mcsharp.net
- 6
- –Р–і—А–µ—Б —А–∞–Ј—А–∞–±–Њ—В—З–Є–Ї–Њ–≤ —П–Ј—Л–Ї–∞ MC# - yury@serdyuk.botik.ru
- 7
- –С–Њ—А–Є—Б–Њ–≤ –Х.–°. –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ —П–Ј—Л–Ї–∞ MC# –і–ї—П —А–µ–∞–ї–Є–Ј–∞—Ж–Є–є –њ–∞—А–∞–ї–ї–µ–ї—М–љ—Л—Е –∞–ї–≥–Њ—А–Є—В–Љ–Њ–≤ –≤ 3D –Љ–Њ–і–µ–ї–Є—А–Њ–≤–∞–љ–Є–Є. http://www.mechanoid.kiev.ua/parallel-mcs-3d-model.html
- 8
- –Ф–Њ—А–Њ—И–µ–љ–Ї–Њ –Р.–Х. –Ь–∞—В–µ–Љ–∞—В–Є—З–µ—Б–Ї–Є–µ –Љ–Њ–і–µ–ї–Є –Є –Љ–µ—В–Њ–і—Л –Њ—А–≥–∞–љ–Є–Ј–∞—Ж–Є–Є –≤—Л—Б–Њ–Ї–Њ–њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ—Л—Е –њ–∞—А–∞–ї–ї–µ–ї—М–љ—Л—Е –≤—Л—З–Є—Б–ї–µ–љ–Є–є. - –Ъ–Є–µ–≤ : –Э–∞—Г–Ї–Њ–≤–∞ –і—Г–Љ–Ї–∞, 2000. - 176 c.
Evgeny S. Borisov
2003-09-27
