
Параллельный вычислитель на аппаратной базе локальной сети персональных компьютеров.
Е.С.Борисов
воскресенье, 7 декабря 2003 г.
1 Введение
Вычислительные системы сверхвысокой производительности стоят дорого. Цена таких систем недоступна для большинства образовательных и научно-исследовательских организаций, но часто существует приемлемая альтернатива - кластер.
Кластер это дешёвый вариант MPP. Обычно это сеть из серийных PC или рабочих станций общего назначения, которая объединяется в ''виртуальную многопроцессорную машину''. Для связи узлов используется одна из стандартных сетевых технологий: Ethernet, Myrinet etc. При достаточном числе узлов, такие системы способны обеспечить вполне удовлетворительную производительность.
Можно использовать уже существующую сеть рабочих станций (системы такого типа иногда называют COW - Cluster Of Workstations). При этом узлы могут иметь различную архитектуру, производительность, работать под управлением разных OC (MS Windows, Linux, FreeBSD).
Если узлы планируется использовать только в составе кластера, то их можно существенно облегчить (отказаться от жёстких дисков, видеокарт, мониторов и т.п.). В облегчённом варианте узлы будут загружаться и управляться через сеть. Количество узлов и требуемая пропускная способность сети определяется задачами, которые планируется запускать на кластере.
2 MPI
Message Passing Interface (MPI) [4] это популярный стандарт для построения параллельных программ по модели обмена сообщениями. Этот стандарт обычно используют в параллельных системах с распределённой памятью (кластера и т.п.).
MPI содержит в себе разнообразные функции обмена данными, функции синхронизации параллельных процессов, механизм запуска и завершения параллельной программы. Стандарт MPI-1 описывает статическое распараллеливание, т.е. количество параллельных процессов фиксировано, это ограничение устранено в новом стандарте MPI-2, позволяющем порождать процессы динамически. MPI-2 в настоящее время находится в стадии разработки.
Разными коллективами разработчиков написано несколько программных пакетов [2], удовлетворяющих спецификации MPI (MPICH, LAM, HPVM etc.). Существуют стандартные ''привязки'' MPI к языкам С, С++, Fortran 77/90, а также реализации [2] почти для всех суперкомпьютерных платформ и сетей рабочих станций.
3 Работа с MPI на кластере
В данной работе для прогона контрольных примеров был использован кластер на основе сети PC и библиотека MPICH [3], созданная авторами спецификации MPI. Этот пакет можно получить и использовать бесплатно. В состав MPICH входит библиотека программирования, загрузчик приложений, утилиты. Существуют реализации этой коммуникационной библиотеки для многих UNIX-платформ, MS Windows.
Для запуска MPI-программ на гомогенном (состоящем из одинаковых узлов, работающих под одной OS) кластере необходимо проделать такие шаги :
- Инсталлировать MPICH на головной узел кластера
(т.е. машину, с которой будем запускать MPI-программы).
Инсталлировать MPICH на все узлы кластера обычно не требуется.
- С сайта MPICH [3] можно бесплатно ''скачать''
исходные коды или ''бинарники'' этой коммуникационной библиотеки.
- Для сети рабочих станций MPICH следует конфигурировать
с параметром --with-device=ch_p4
$./configure --with-device=ch_p4 \ --with-arch=freebsd \ -prefix=/usr/local/mpich \ -rsh=rsh ... $ make ... $ make install
- Если вы используете OS FreeBSD [5],
то можно воспользоваться портом mpich
$ cd /usr/ports/net/mpich $ make all install
- С сайта MPICH [3] можно бесплатно ''скачать''
исходные коды или ''бинарники'' этой коммуникационной библиотеки.
- MPICH использует rsh (remote shell) для запуска процессов на
узлах кластера. Поэтому необходимо запустить на каждом узле rshd
(remote shell server) и согласовать права доступа.
Для обеспечения более высокого уровня сетевой безопасности можно использовать ssh - OpenSSH remote login client.
- Компиляция MPI-программы на языке С выполняется
утилитой mpicc, представляющей собой надстройку над C-компилятором,
установленным в данной OS.
mpicc myprog.c -o myprog - Перед запуском ''бинарника'' myprog необходимо разослать его
на все узлы кластера, причём локальный путь до myprog должен быть
одинаковый на всех машинах, например - /usr/mpibin/myprog.
Вместо процедуры копирования программы на узлы можно использовать NFS (Network File System) :
- на головной машине поднимаем NFS-сервер и открываем каталог с myprog
- на каждом рабочем узле кластера, монтируем NFS головной машины, используя единый для всех узлов локальный путь.
- Запуск MPI-программы производится командой :
mpirun -machinefile machines -np n myprog- machines - файл, содержащий список узлов кластера
- n - количество параллельных процессов
- После команды mpirun, MPICH, используя rsh, запускает
n-раз программу myprog на машинах из machines.
В идеале : 1 процессор - 1 процесс. - При запуске каждому процессу присваивается уникальный номер :
...
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
...далее программа работает исходя из этого номера :
...
if (myid == N) { ПОДПРОГРАММА_ДЛЯ_ВЕТКИ_N(); }
...
3.1 Пример MPI-программы
Рассмотрим классический пример параллельного программирования -
вычисление ![]() . Число
. Число ![]() будем вычислять как
определённый интеграл :
будем вычислять как
определённый интеграл :
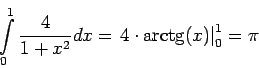
Согласно правилу прямоугольников интеграл можно заменить суммой:
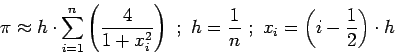
Текст программы [ здесь ]
3.2 Результаты счета
- Одна машина
Время счета для n=109 - 108 секунд[ mpibin ]$ ./pi Process 0 on node2.home.net n = 1000000000 pi = 3.1415926535899708 time = 108.807704 sec.
- Две машины
Время счета для n=109 - 57 секунд[ mpibin ]$ mpirun -machinefile machines -np 2 pi Process 0 on node2.home.net Process 1 on node1.home.net n = 1000000000 pi = 3.1415926535899708 time = 57.040686 sec.
Литература
- 1
- Коммуникационные библиотеки - http://www.parallel.ru/tech/tech_dev/ifaces.html
- 2
- Технология параллельного программирования MPI - http://parallel.ru/tech/tech_dev/mpi.html
- 3
- MPICH - http://www-unix.mcs.anl.gov/mpi/mpich
- 4
- MPI - http://www.mpi-forum.org
- 5
- FreeBSD - http://www.freebsd.org
Evgeny S. Borisov
2003-12-07
