
[ на главную ]
Deep learning. Stacked Autoencoders.
Методы обучения нейронных сетей с большим количеством скрытых слоёв.
Е.С.Борисов понедельник, 21 марта 2016 г.
1. Введение.
Математические модели биологического нейрона появились ещё в середине прошлого века [1]. Потом были первые модели нейронных сетей с одним обрабатывающим слоем, возможности которых были ограничены проблемой линейной неразделимости. Позже появился метод обратного распространения [2] -- способ позволяющий эффективно обучать нейронные сети с одним или двумя скрытыми слоями. Многослойный перцептрон с тремя обрабатывающими слоями имеет возможность строить в пространстве признаков поверхности практически любой формы. Однако трёхслойный перцептрон уступал по эффективности другим методам. Предполагалось, что его результаты можно улучшить увеличив число слоёв. До недавнего времени не удавалось эффективно обучать нейронные сети с числом скрытых слоёв более двух. Одной из причин является проблема "исчезающего" градиента (vanishing gradient) [3] -- при вычислении градиента (направления наибольшего роста ошибки сети в пространстве весовых коэффициентов) методом обратного распространения происходит его уменьшение по мере прохождения от выходного слоя сети к входному. Эту проблему пытались решать разными способами - увеличивать количество циклов обучения, увеличивая размеры учебного набора, сокращая количество связей сети, инициализируя матрицы весов специальным образом и т.п. Наращивание вычислительных возможностей с помощью технологий параллельных вычислений (GPU) дало дополнительные возможности исследователям. В результате этих усилий в середине 2000-х годов появилась концепция deep learning [4](глубокое или глубинное обучение). Deep learning [5] рассматривает многоуровневые (представленные несколькими слоями) модели интеллектуальных систем, такие как искусственные нейронные сети. Кратко это можно описать следующим образом - много данных через большое количество слоёв с большим количеством нейронов. Реализации этих идей помогли достичь очень хороших результатов при решения задач классификации и др. В рамках концепции deep learning были созданы различные модели искусственных нейронных сетей. Далее мы рассмотрим одно из решений проблемы "исчезающего" градиента для многослойной искусственной нейронной сети прямого распространения (MPL), но перед этим необходимо рассмотреть модель под названием автокодировщик (autoencoder).2. Модель autoencoder.
Обычный autoencoder [6] это трёхслойная нейронная сеть прямого распространения, в которой вторая половина сети зеркально повторяет первую (Рис.1). Как следует из названия, autoencoder отображает входной образ в себя, т.е. эта сеть обучается таким образом, что бы воспроизводить учебное множество.
Рис.1: Autoencoder
Рис.2: Autoencoder с шумоподавлением
3. Предобучение многослойной нейронной сети с помощью autoencoder.
Искусственные нейронные сети прямого распространения с большим количеством слоёв плохо обучаются обычными способами, которые хорошо работают для сетей с одним скрытым слоем, потому как имеет место проблема "исчезающего" градиента, т.е. чем дальше слой от выхода тем меньше получаются значения изменения его весов. Эту проблему можно решить "правильно" выбрав начальные значения весов. Тогда нам не потребуется значительно их менять в процессе обучения и малые значения градиента на первых слоях сети нас вполне удовлетворят. Таким образом процедура обучения сети разделилась на следующие две фазы.- предобучение сети (pretraining)
- тонкая подстройка весов (fine-tuning)
- загрузка учебного набора данных X0
- определить параметры сети - количество (N) и размеры слоёв
установить номер текущего слоя i=0 - построить автоенкодер для слоёв i, i+1
- обучить автоенкодер на наборе Xi
- убрать вспомогательный (выходной) слой автоенкодера
- сохранить веса Wi связей слоёв i,i+1
- если есть ещё пары слоёв для обработки (i<N-2)
то переход на следующий пункт
иначе переход на п.10 - сгенерировать набор данных Xi+1 для следующего автоенкодера,
для этого пропустить через пару слоёв i,i+1 набор данных Xi - переход п.3
- конец работы
4. Реализация.
В этом разделе представлена реализация классификатора распознающего изображения с цифрами. Классификатор построен на основе глубокой сети прямого распространения, обучаемой методом описанным выше. В качестве набора данных будем использовать часть базы MNIST [10] (7000 образов случайно выбранных из полного набора в 70 тысяч).

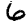
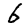

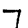
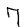
Рис.: примеры из набора MNIST
4.1 Простая сеть.
Конфигурация сети:784 нейрона - входной слой,
500 нейронов - активация ReLU,
10 нейронов - активация softmax Обучение методом простого градиентного спуска.
Наилучший результат : 89 ошибок на 1000 тестовых примеров

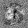
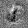



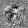




















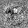







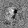




Рис.:карта весов первого слоя простой сети
4.2 Глубокая сеть.
Конфигурация сети:784 нейрона - входной слой,
500 нейронов - активация ReLU,
300 нейронов - активация ReLU,
100 нейронов - активация ReLU,
50 нейронов - активация ReLU,
10 нейронов - активация softmax Предобучение методом contrastive divergence,
Тонкая настройка весов методом простого градиентного спуска.
Наилучший результат : 49 ошибок на 1000 тестовых примеров





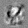
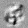
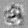





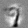






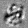


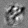

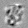




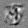
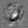






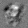
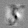
Рис.:карта весов первого слоя глубокой сети





























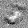










Рис.:карта весов первого слоя глубокой сети без предобучения
Список литературы
- Е.С.Борисов Основные модели и методы теории искусственных нейронных сетей.
-- http://mechanoid.kiev.ua/neural-net-base.html - Е.С.Борисов О методах обучения многослойных нейронных сетей прямого распространения.
-- http://mechanoid.kiev.ua/neural-net-backprop.html - Павел Нестеров Предобучение нейронной сети с использованием ограниченной машины Больцмана.
-- https://habrahabr.ru/post/163819/ - G.E.Hinton and R.R.Salakhutdinov Reducing the Dimensionality of Data with Neural Networks. 28 JULY 2006 VOL 313 SCIENCE. -- http://www.cs.toronto.edu/~hinton/science.pdf
- Deep Learning -- http://deeplearning.net
- Andrew Ng CS294A Lecture notes. Sparse autoencoder.
-- http://nlp.stanford.edu/~socherr/sparseAutoencoder_2011new.pdf - Е.С.Борисов Ассоциативная память на основе ограниченной машины Больцмана (RBM).
-- http://mechanoid.kiev.ua/neural-net-boltzman-restr.html - G.E.Hinton Neural Networks for Machine Learning -- http://www.coursera.org/course/neuralnets
- Hugo Larochelle Neural networks class
-- http://www.youtube.com/playlist?list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH - The MNIST database of handwritten digits -- http://yann.lecun.com/exdb/mnist/
- Deep Learning Tutorial: Stacked denoising auto-encoders (SdA)
-- http://deeplearning.net/tutorial/deeplearning.pdf
