
О методе кодирования слов word2vec.
Евгений Борисов понедельник, 7 июня 2017 г.1. Введение
Применение методов машинного обучения к текстам на естественных языкак может дать много интересных и полезных результатов [1], например - автоматическая сортировка текстов по темам (задача классификации), поиск похожих текстов (задача кластеризации), автоматический перевод и др. Для того, чтобы применить математические методы к текстам необходимо определённым образом формализовать данные [2]. В случае классификатора текстов [1] формализация выполняется с помощью частотного анализа ($g$), в этом случае мы каждому тексту $T$ ставим в соответствие точку в пространстве признаков $X\subset \mathbb{R}^n$. $$g: T \rightarrow X $$ Этот метод достаточно хорошо работает для текстов среднего размера, однако для коротких сообщений частотная характеристика может оказаться неинформативной. Не годиться этот подход и для задач машинного перевода, где нас интересует не общая характеристика текста, но каждое слово в отдельности и последовательности из слов. Таким образом, возникает необходимость построить эффективный метод кодирования отдельных слов.2. О способе кодирования слов
Слова можно кодировать разными способами. Наверно самый простой способ это их занумеровать, т.е. составляем полный словарь из текста, собраем все возможные словоформы, использованные в тексте, и нумеруем все эти слова. Но такой способ кодирования не несёт никакой смысловой нагрузки, т.е. по коду нельзя сказать насколько близкими по смыслу являются слова, например, номер 7 и номер 457. Для построения "осмысленного" пространства для слов был разработан метод word2vec [3], который отображает слова $W$ в векторное пространство $V\subset \mathbb{R}^n$. $$ word2vec: W \rightarrow V $$ При этом, совместно употребляемые в тексте $T$ слова из $W$ отображаються в близкие (в смысле евклидовой метрики) точки пространства $V$. К тому же, над точками $V$ можно выполнять операции имеющие смысл в $W$. Приведём ниже пример. $$ word2vec[king] - word2vec[man] + word2vec[woman] \approx word2vec[queen] $$ Далее мы рассмотрим метод кодирования word2vec подробней.3. word2vec
Результатом работы word2vec является набор векторов (матрица) - кодов слов, которая получается с помощью обучения определённой нейросети на некотором тексте (упорядоченном множестве слов), и первое, что нужно сделать это подготовить набор учебных данных.3.1 подготовка учебного набора
Набор учебных данных для нейросети word2vec конструируем следующим образом.- Очищаем входной текст $T$ от лишних символов (знаки препинания и т.п.).
- Из очищенного текста $T$ собираем словарь $W$.
- Для каждого слова $w_i \in T$ собираем контекст, т.е. набор слов $C_i\subset T$, удалённых от $w_i$ не более чем на $s$ позиций в последовательности слов $T$. $$ C_i = \{ w_j \in T : (i-s) \leq j \leq (i+s), j \neq i \} $$ иначе говоря - $C_i$ это слова $w_j\in T$ из $s$-окрестности слова $w_i\in T$
- выполняем унитарное кодирование [4] (one-hot encoding) словаря $W$, т.е. каждому слову $w_i\in W$ ставиться в соответствие вектор $u_i \in U$ из нулей и одной единицы, длинна вектора $u_i$ равна размеру словаря $W$, позиция единицы в векторе $u_i$ соответствует номеру слова в словаре $W$.
- заменяем слова в тексте $T$ и контекстах $C$ соответствующими кодами $P$ и $Q$ из $U$.
Pi: 0 0 1 0 0 Qi: 0 1 0 0 0 0 0 0 0 1 0 0 0 1 0 1 0 0 0 0 0 0 0 1 0
Листинг 1: пример кодов (слово и контекст)
3.2 нейросеть word2vec
Нейросеть word2vec имеет следующий вид (рис.1).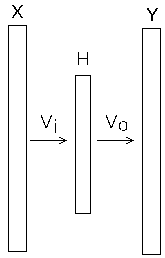
Рис 1: схема нейронной сети word2vec
- Skip-Gram [5] - по слову восстанавливаем контекст.
- CBOW (Continuous Bag of Words) [6] - по контексту восстанавливаем слово.
3.3 Skip-Gram
Как уже говорилось выше, основная идея метода Skip-Gram [5] обучения нейросети word2vec заключается в восстановлении слов контекста по текущему слову (рис.2).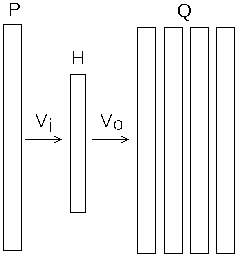
Рис 2: схема нейронной сети word2vec (Skip-Gram )
- На вход сети подаётся код слова $P$, вычисляем состояние скрытого слоя $H$ $$ H = P \cdot V_i $$
- далее вычисляем выход сети $O$, $$ U = H\cdot V_o \\ O = softmax(U) $$
- для каждого слова контекста $Q_j$ и входа $P$,
вычисляем ошибку $D$ на выходе сети $O$ и изменение весов сети $\Delta Vo$, $\Delta Vi$. $$ D = O - Q_j \\ \Delta Vo_j = H^T \cdot D \\ \Delta Vi_j = D^T \cdot P \cdot Vo^T ; $$ - вычисляем суммарное изменение весов сети $\Delta Vo$, $\Delta Vi$. $$ \Delta Vo = \sum_j \Delta Vo_j \\ \Delta Vi = \sum_j \Delta Vi_j $$
3.4 CBOW
Альтернативой Skip-Gram служит стратегия CBOW [8], здесь мы по контексту пытаемся восстановить слово (рис.3).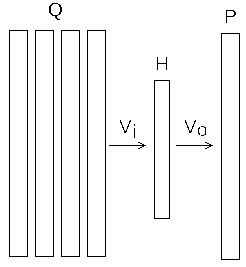
Рис 3: схема нейронной сети word2vec (CBOW)
- На вход сети подаётся усреднённое значение контекста $Q$, вычисляем состояние скрытого слоя $H$ $$ H = \frac{1}{c}\sum_{j=1}^c Q_j \cdot Vi $$
- далее вычисляем выход сети $O$, $$ U = H\cdot V_o \\ O = softmax(U) $$
- для каждого слова контекста $Q_j$ и кода слова $P$,
вычисляем ошибку $D$ на выходе сети $O$ и изменение весов сети $\Delta Vo$, $\Delta Vi$. $$ D = O - P \\ \Delta Vo = H^T \cdot D \\ \Delta Vi = \sum_j D^T \cdot Q_j \cdot Vo^T ; $$
4. Реализация
В этом разделе представим реализацию word2vec, эта реализация состоит из трёх частей:- кодировщик - на вход поступает очищенный текст, на выходе имеем кодированные наборы слов текста $P$ и контекстов $Q$.
- обучение сети - на вход поступает учебный набор $P,Q$, на выходе имеем матрицу представлений $Vi$
- тест результата - на вход поступает словарь и матрица представлений $Vi$, на выходе имеем случайно выбранные слова из словаря и наиболее близкие к ним слова по word2vec.
| слово | близкие по w2v |
|---|---|
| смотрит | подозрительно, кровати |
| при | приворовываешь, чём |
| она | семья, разваливается |
| ещё | важно, поучительно |
| самого | конца, последней |
| алкоголик | покуриваешь, травку |
| способности | определённые, солнца |
| ответственность | странице, авторской |
| портал | произведения, читателей |
| разваливается | знаю, семья |
| рецензию | написать, рукой |
| подобию | господа, образу |
Листинг 2: результаты работы
Литература
- Е.С.Борисов Автоматизированная обработка текстов на естественном языке, с использованием инструментов языка Python
- http://mechanoid.kiev.ua/ml-text-proc.html - Е.С.Борисов О методах обучения многослойных нейронных сетей прямого распространения.
- http://mechanoid.kiev.ua/neural-net-backprop.html -
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean
Distributed Representations of Words and Phrases and their Compositionality
- https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf - Унитарный код - http://ru.wikipedia.org/wiki/Унитарный_код
-
Alex Minnaar Word2Vec Tutorial Part I: The Skip-Gram Model, 12 April 2015
- http://alexminnaar.com/author/alex-minnaar.html -
Alex Minnaar Word2Vec Tutorial Part II: The Continuous Bag-of-Words Model, 18 May 2015
- http://alexminnaar.com/author/alex-minnaar.html - Е.С.Борисов Обучение нейронных сетей градиентными методами первого порядка.
- http://mechanoid.kiev.ua/neural-net-backprop2.html -
Xin Rong word2vec Parameter Learning Explained
- http://arxiv.org/abs/1411.2738
