
Кластеризатор на основе алгоритма k-means.
Евгений Борисов
четверг, 6 февраля 2014 г.
1 Введение
Кластеризация или естественная классификация это процесс объединение в группы объектов, обладающих схожими признаками. В отличие от обычной классификации, где количество групп объектов фиксировано и заранее определено набором идеалов, здесь ни группы и ни их количество заранее не определены и формируются в процессе работы системы исходя из определённой меры близости объектов. Существует несколько основных методов разбиения групп объектов на кластеры. В данной статье описан кластеризатор на основе алгоритма k-means [1,2].
2 Постановка задачи
Рассмотрим набор точек X в n-мерном пространстве признаков
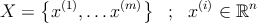
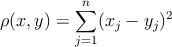
Необходимо разбить это множество на K частей или кластеров ( K < m ), объеденив близкие элементы. Кластеры можно определить с помощью особых точек-центроидов μ i ∈ ℝ n ; ( i = 1 , … K ) . Точка x ( i ) принадлежит кластеру k если расстояние ρ до центроида k минимально.
Задача сводиться к нахождению точек-центройдов μ .
3 Решение
Для определения центройдов μ будем использовать алгоритм k-means. На первом этапе случайным образом инициализируются центройды. Далее на каждой итерации центройды сдвигаются по определённым правилам. Алгоритм выглядит следующим образом.
- случайным образом инициализровать центройды μ
-
для каждого центройда
μ
k
вычислить расстояния
lk(i)
до всех точек
x
(
i
)
lk(i) = ρ ( x(i) , μk ) - сформировать кластеры,
для каждого центройда μ k из множества X отобрать подмножество точек X k с минимальным расстоянием до μ k
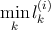
- вычислить новые центройды как среднее всех точек кластера
X
k
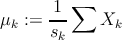
где s k – количество точек в кластере k
- если значения
μ
k
изменились (центройды сдвинулись)
то переход на п. 2
иначе конец работы
Результат работы этого алгоритма сильно зависит от начальной инициализации цетройдов.
Рассмотрим функцию оценки Q качества работы кластеризатора.
c – количество кластеров;Для получения наилучшего результата можно несколько раз выполнить алгоритм кластеризации, после чего выбрать результат с наименьшим значением Q .
di – среднее внутрикластерное расстояние;
do – среднее межкластерное расстояние;
|
|


|
|


Реализация в системе Octave [ здесь ].
Список литературы
[1] Andrew Ng Machine Learning – http://www.coursera.org/course/ml
[2] k-means: Википедия – http://ru.wikipedia.org/wiki/K-means
