
Классификатор на основе решающего дерева
Евгений Борисов
понедельник, 26 мая 2014 г.
В этой статье мы поговорим о методе классификации, который носит название решающее дерево. Алгоритм построения решающего дерева рекурсивно разделяет исходное множество точек на две части, до тех пор пока в каждое, полученное таким образом, подмножество будет содержать точки только одного типа.
Для построения разделительных гиперплоскостей в пространстве признаков, этот метод использует понятие информативности.
1 Информативность
Рассмотрим множество точек X, и некоторый классификатор φ(X) → { 0, 1}.
Неформально – классификатор φ тем более информативен, чем больше он выделяет объектов ”своего” класса по сравнению с объектами всех остальных ”чужих” классов.
Свои объекты назовём позитивными, а чужие – негативными.
Введём следующие обозначения:
P ≥ 1 – число объектов класса c в выборке X
p(φ) – из них число объектов, для которых выполняется условие φ(x) = 1 (правильный результат)
N ≥ 1 – число объектов всех остальных классов в выборке X
n(φ) – из них число объектов, для которых выполняется условие φ(x) = 1 (ошибки классификатора)
Информативность классификатора φ тем выше, чем больше объектов он выделяет, и чем меньше среди них негативных.
Введём формальное определение информативности.
Рассмотрим два исхода w0,w1 с вероятностями q0 и q1 = 1 −q0, количество информации, связанное с исходом wi, по определению равно − log 2qi. Это математическое ожидание числа бит, необходимых для записи информации о реализации исходов wi.
Энтропия определяется как мат.ожидание количества информации:
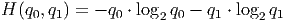
Будем считать появление объекта класса c исходом w0, а появление объекта любого другого класса исходом w1. Тогда можно оценить энтропию выборки X:
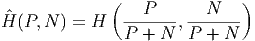
Энтропия всей выборки после получения информации φ становится равна:
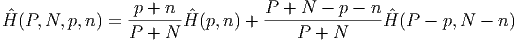
В итоге уменьшение энтропии составляет
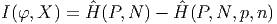
Это есть энтропийное определение информативности.
2 Построение решающего дерева
Рассмотрим учебный набор (X,Y ) в n-мерном пространстве признаков, где X – объекты, Y – соответствующие объектам номера классов. Процедура построение решающего дерева представляем собой рекурсивное разделение этого множества точек на две части с максимизацией информативности этого разделения на каждом шаге.
Алгоритм обучения выглядит следующим образом.
- если X содержит точки только одного класса
то переход на п.6 - выбрать признак номер i и найти для него пороговое значение b
( min(Xi) < b < max(Xi) ) с максимальной информативностью
разделения
![φi(b) = φ(X, i,b) = [Xi > b]](content/ml-dtree.html/index4x.png)
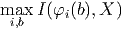
- сохранить найденную пару (i,b)
- разделить X на две части по признаку i и его порогу b
- выполнить рекурсивно с п.1 для каждого полученного на пред.шаге подмножества
- конец работы
3 Реализация
На рисунке ниже проиллюстрирована результаты работы решающего дерева
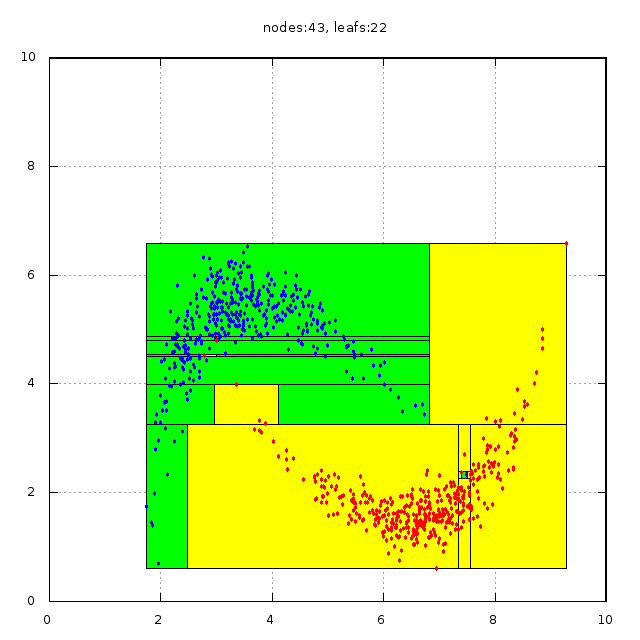 |
| Рис.1: результат работы |
Реализация в системе Octave [ здесь ].
Список литературы
[1] Воронцов К.В. Логические методы классификации – http://shad.yandex.ru/lectures/machine_learning.xml
