
Сегментация изображения текста
Евгений Борисов
суббота, 9 августа 2008 г.
1 Введение
При рассмотрении задачи оптического распознавания текста (OCR) возникает проблема сегментации символов или выделения изображений отдельных символов на картинке с изображением текста. В этой статье предлагается решение такой задачи сегментации, основанное на работе [1].
В данном случае мы предполагаем, что изображение текста правильно ориентированно, т.е. строки ровные и картинка не повёрнута относительно наблюдателя (рис.1).

Сегментацию изображения текста будем проводить в три этапа:
- выделение строк - исходное изображение текста необходимо "разрезать" на полосы-строки нужной ширины.
- сегментация слов - в изображении текстовой строки выделяем изображения слов.
- сегментация символов - в изображении слова проводим границы символов.
Будем рассматривать изображение текста в градациях серого. Исходное изображение можно представить как матрицу яркостей точек B
0≤bij≤bmax
i=1... n ; j=1... m
где n - ширина картинки, m - высота картинки
Для определённости будем считать, что максимальное значение яркости (bmax ) соответствует чёрному цвету а минимальное (равное 0) - белому.
2 Сегментация строк
Задача выделения строк сводиться к нахождению верхних и нижних граней строк текста, изображённого на исходной картинке.
Алгоритм сегментации строк основывается на том, что средняя яркость в изображениях межстрочных промежутках существенно ниже средней яркости в изображениях текстовых строк.
- Сначала для всех пиксельных строк исходного изображения находим их
средние значения яркости
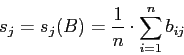
- Затем определяем среднее значение яркости всего изображения
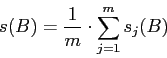
- Средняя яркость в межстрочных промежутках текста должна быть невелика
(в идеальном случае она равна нулю). Поэтому яркость верхней границы
текстовой строки можно выразить через среднюю яркость изображения
st= kt * s(B)
где 0<kt<1 - коэффициент - Аналогично яркость нижней границы текстовой строки,
также может быть выражена через среднюю яркость всего изображения
sb= kb * s(B)
где 0<kb<1 - коэффициент
Работа алгоритма сегментации строк заключается в последовательном просмотре массива средних значений (s1,...,sm) и выявлении множества пар индексов (sti,sbi) пиксельных строк, соответствующих верхней sti и нижней sbi граням изображения строки номер i, удовлетворяющих следующим условиям.
- Условия верхней границы текстовой строки.
Начало текстовой строки или области устойчивого повышения яркости фиксируется, если выполняется следующий комплекс условий:
- яркость текущей пиксельной строки превышает границу st
- яркость двух предыдущих пиксельных строк ниже этой границы
- яркость трех последующих строк выше границы sb
т.е. в пиксельной строке с номером i начинается изображение текстовой строки если
(si-2 < st) ^ (si-1 < st) ^ (si > sb) ^ (si+1 > sb) ^ (si+2 > sb) ^ (si+3 > sb)
- Условия нижней границы текстовой строки.
Конец области устойчивого повышения яркости определяется, если выполняется следующие условия:
- было зафиксировано начало области
- яркость текущей пиксельной строки превышает границу st
- яркость последующей пиксельной строки ниже границы sb
Или:
- было зафиксировано начало области
- яркость трех последующих строк ниже границы sb
т.е. в пиксельной строке с номером i заканчивается изображение текстовой строки, если ранее было определено, что строка началась, и выполняется условие
( (si > st) ^ (si+1 < sb) ) v ( (si+1 < sb) ^ (si+2 < sb) ^ (si+3 < sb) )
В результате формируется множество пар индексов верхних и нижних граней строк. Разность между этими индексами дает высоты текстовых строк. Однако такой алгоритм находит среднюю высоту каждой текстовой строки и "срезает" символы, выступающие по высоте за эту среднюю высоту.
Чтобы избежать этого, необходимо расширить найденные границы. Можно предложить следующий алгоритм расширения границ. Среди найденных текстовых строк определяется строка с минимальной высотой Hmin и, затем все границы с каждой стороны расширяются на величину 0.3 * Hmin. Это не приводит к слиянию строк, т.к. межстрочные интервалы текста, как правило, больше чем высота строки (рис.2).

Таким образом, в результате работы алгоритма на исходном изображении отмечается положение всех текстовых строк.
3 Сегментация слов
На втором этапе решения задачи сегментации изображения текста, из изображений строк. Входом для алгоритма сегментации слов служит изображение, какой либо одной текстовой строки, которое получается из исходного изображения документа после применения к нему алгоритма сегментации строк (рис.3).
Для улучшения качества работы алгоритма выделения слов из строки вначале его работы выполняются два преобразования входного изображения.
- Пороговый фильтр повышения контрастности
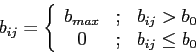
где i=1... n ; j=1... m ; b0 - порог яркости
Такое преобразование, при правильно выбранном пороге b0, помогает снизить уровень шума, т.е. убрать значительное количество лишних точек (рис.4).
- "Размазывающий" фильтр - для каждой яркой(чёрной) точки исходного
изображения закрашиваем соседние точки.
В результате такого преобразования близкие точки объединяются в непрерывную область и вместо множества маленьких точек получаем картинку состоящую из нескольких сплошных пятен с достаточно чёткой границей (рис.5).

Далее выполняем собственно процедуру сегментации. Алгоритм сегментации слов основывается на том, что средняя яркость в межсловных интервалах существенно ниже средней яркости в изображениях слов. Он похож на алгоритм сегментации строк, только просмотр идет по пиксельным столбцам изображения строки.
- Для всех пиксельных столбцов исходного изображения строки
находим их средние значения яркости
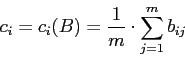
где m, - высота текущей строки в точках
- Затем определяем среднее значение яркости для данного изображения строки
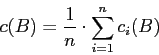
где n, - ширина текущей строки в точках
- Средняя яркость в межсловных интервалах должна быть невелика (в
идеальном случае она равна нулю). Поэтому ее левую границу (начало слова)
можно выразить через среднюю яркость изображения строки
cl= kl * c(B)
где 0<kl<1 - коэффициент - Аналогично яркость правой границы (конец слова),
также может быть выражена через среднюю яркость всего изображения
cr= kr * c(B)
где 0<kr<1 - коэффициент
Работа алгоритма сегментации слов заключается в последовательном просмотре множества средних значений яркости столбцов (c1,...,cn) и выявлении множества пар индексов (cli,cri) пиксельных строк, соответствующих левой cli и правой cri граням изображения слова номер i, удовлетворяющих следующим условиям (рис.6).
- Условия левой границы (начало слова).
Начало слова или области устойчивого повышения яркости фиксируется, если выполняются следующие условия;
- яркость текущего и последующего пиксельного столбца превышает левую границу яркости для слова cl
- яркость предыдущего пиксельного столбца ниже этой границы
т.е. в пиксельном столбце с номером j начинается изображение слова если
(cj-1 < cl) ^ (cj > cl) ^ (cj+1 > cl)
- Условия правой границы (конец слова).
Конец области устойчивого повышения яркости определяется, если выполняются следующие условия;
- было зафиксировано начало слова
- яркость текущего и четырех последующих пиксельных столбцов ниже границы яркости межсловного интервала cr
- яркость двух предыдущих пиксельных столбцов выше этой границы
т.е. слово заканчивается в пиксельном столбце с номером j , если ранее было определено, что слово началось, и выполняется условие
(cj-2 > cr) ^ (cj-1 > cr) ^ (cj < cr) ^ (cj+1 < cr) ^ (cj+2 < cr) ^ (cj+3 < cr) ^ (cj+4 < cr)
4 Сегментация символов
В большинстве изображений слов символы расположены близко друг к другу и межсимвольные интервалы не так ярко выражены, как в случае межстрочных или межсловных интервалов (рис.7). Поэтому алгоритм сегментации символов сложнее и не так очевиден как рассмотренные ранее алгоритмы сегментации строк и слов.
Входом для алгоритма сегментации символов служит изображение, какого либо слова, которое получается из изображения текстовой строки после применения к нему алгоритма сегментации слов.
Алгоритм сегментации символов основывается на том, что средняя яркость в межсимвольных интервалах, по крайней мере, ниже средней яркости в изображениях символов. Его (алгоритма сегментации) общая схема состоит из двух основных частей.
- находим все индексы столбцов, соответствующие локальным минимумам средней яркости столбцов ci.
- выявляем и удаляем из этого списка индексов ложные границы символов
Конечная цель работы - найти индексы столбцов-границ между символами.
4.1 Поиск локальных минимумов яркости
Поиск локальных минимумов средней яркости столбцов
ci
происходит на смежных
интервалах изменения индекса столбца.
Размер интервала выбирается исходя из высоты строки.
Для большинства шрифтов отношение ширины символа к его высоте не превышает
величину
0.3. Поэтому размер интервала выбран
где m - высота слова в точках.
Поиск минимумов работает следующим образом.
- Сначала для всех пиксельных столбцов исходного изображения находим их
средние значения яркости
где m - высота слова в точках.
- Среди значений ci первый минимум ищем на отрезке i=1,...,dj.
- Предположим, что он нашелся для индекса i1min.
- Следующий минимум ищем на отрезке i=(i1min+1),...,(i1min+1+dj).
- Процедура поиска повторяется, до достижения границы ( i=n ) изображения слова. Все значения индекса ijmin , соответствующих локальным минимумам, сохраняются в списке W0 (рис.8).
4.2 Удаление ложных границ
Удаление ложных межсимвольных границ будем проводить в несколько этапов.
- Локальный минимум яркости в столбце номер
i
является "кандидатом"
на принадлежность к межсимвольному интервалу, если значение средней
яркости
ci
в этом столбце меньше определённой границы яркости
cb
и при этом значение средней яркости в столбцах отстоящих от данного
локального минимума на 2 пикселя слева или справа больше границы яркости.
Границу яркости можно определить через среднюю яркость картинки.
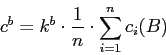
где 0<kb<1 . - коэффициент, n - ширина изображения слова в точках.Первое условие межсимвольных границы можно записать в следующем виде.
(ci < cb) ^ ( (ci-2 > cb) v (ci+2 > cb) )
В результате из списка индексов локальных минимумов W0 удаляются индексы столбцов, средняя яркость которых не удовлетворяет этому условию, формируется второй список W1 индексов-"кандидатов" в межсимвольные границы (рис.9).
- Выявление связей между столбцами пикселей.
На этом шаге алгоритма сегментации будем анализировать связность изображений
символов и убирать из списка
W1
ложные границы, которые разрезают
символ на части. Это может происходить с широкими слабосвязанными
символами, например символы русского алфавита П, Н, Ц.
Причём, символ может быть связан, либо в верхней (П), либо в средней
(Н), либо в нижней части (Ц) пиксельных столбцов. Чтобы избежать
неправильной классификации связности, разделим изображение на три уровня
по вертикали и будем анализировать эти уровни отдельно друг от друга.
Разделение изображения символа на части происходит в следующей пропорции:
верхний уровень - 30% от высоты символа,
средний уровень - 40% от высоты символа,
нижний уровень - 30% от высоты символа.
Сформулируем условия связности двух соседних пиксельных столбцов k и k+1.
- Для максимумов яркости трех уровней
bk h1,bk m1,bk l1
столбца
k
и максимумов яркости трех уровней
b(k+1) h2,b(k+1) m2,b(k+1) l2
столбца
k+1
должно выполняться условие
( h1= h2 ) v ( m1 = m2 ) v ( l1 = l2 )
- Средняя яркость столбца
k
должна быть меньше максимума яркости соседнего столбца
k+1
c(k) < cmax(k+1)
- максимум яркости в столбце
k
должен быть больше удвоенного
абсолютного значения разности между значениями максимумов яркости столбца
k
и соседнего столбца
k+1
cmax(k) > 2 * | cmax(k) - cmax(k+1) |
Если для данного столбца выполняются все условия связности с соседями слева и справа то граница удаляется как ложная, в противном случае выполняется ещё одна проверка. Расстояние до предыдущей (левой) границы dk должно быть больше допустимого минимума dmin.
dk > dmin.
dmin= 0.4 * n.где n - высота изображения словаВ результате из списка индексов "кандидатов" W1 удаляются индексы столбцов, которые имеют связь с соседями слева и справа, формируется конечный список индексов границ W2 (рис.10).
- Для максимумов яркости трех уровней
bk h1,bk m1,bk l1
столбца
k
и максимумов яркости трех уровней
b(k+1) h2,b(k+1) m2,b(k+1) l2
столбца
k+1
должно выполняться условие


Исходные тексты программы [ здесь ]
Литература
- 1
- Распознавание текстовых изображений - http://ocr.apmath.spbu.ru
Evgeny S. Borisov
2008-08-09
