
О задаче поиска объекта на изображении.
Часть 2: Применение методов машинного обучения.
Евгений Борисов
понедельник, 24 июля 2017 г.
1. Введение
В первой части статьи мы рассмотрели простые способы поиска объекта на изображении. Однако, область их применения ограничена по той причине, что все они имеют плохую обобщающую способность. Это значит, что модель описывает один конкретный объект или очень узкий класс объектов. Например, автомобиль может выглядеть по-разному, в зависимость от марки, положения наблюдателя и др. Для того, чтобы успешно распознавать не один объект но большие и разнообразные классы объектов, можно применять методы машинного обучения. Если рассматривать задачу поиска объектов на видео, то её можно разделить на три подзадачи - обнаружение, распознавание и сопровождение.- обнаружение (detection) - выделяем области на изображении, которые могут содержать интересующий нас объекты,
- распознавание (recognition) - уточняем типы найденных объектов,
- сопровождение (tracking) - локализация на следующих кадрах распознанных объектов.
2. Гистограммы направленных градиентов (HOG)
Гистограмма направленных градиентов (Histogram of Oriented Gradients, HOG) [1] - метод извлечения признаков из изображений, который очень похож на метод вычисления дескрипторов SIFT [2] для особых точек, только вычисляем его не для окрестности особой точки, но для всего изображения. Общая схема вычисления HOG выглядит следующим образом. Картинка разделяется на части (ячейки), для каждой ячейки строим гистограмму направлений градиента яркости, далее гистограммы ячеек нормируются по контрасту и объединяются. Подробней про HOG можно послушать лекцию [3]. Пример использования HOG мы разберём ниже - в разделе о задаче локазизации объектов на изображении.3. Мешок слов (BoW)
Мешок слов ( Bag of visual Words, BoW ) [4] - метод извлечения признаков из изображений, который является адаптацией для изображений метода частотного анализа текстов (TF, term frequency) [5]. Применение методов машинного обучения для распознавания объектов на изображении предполагает наличие учебного набора, состоящего из двух (как минимум) частей (классов):- набор изображений содержащих объект (позитивные примеры),
- набор изображений объект не содержащих (негативные примеры).
- выбираем метод выявления особых точек и метод вычисления для них дескрипторов
- для каждого изображения, входящего в учебный набор, определяем особые точки и вычисляем для них дескрипторы
- объединяем похожие дескрипторы в группы, т.е. выполняем кластеризацию [6] множества полученных дескрипторов
- выбранным на этапе составления словаря методом, определяем особые точки на изображении и вычисляем для них дескрипторы
- разбираем найденные дескрипторы по кластерам словаря
- для каждого кластера словаря считаем количество найденных дескрипторов
4. Признаки Хаара
Признак Хаара (Haar-like features) [8] вычисляется следующим образом.- Выбираем прямоугольную область на изображении,
- разбиваем её на несколько смежных прямоугольных частей,
- в каждой части суммируем яркость точек,
- после чего вычисляем разность между этими суммами.

Рис.1: признаки Хаара

Рис.2: признаки Хаара в методе Виолы-Джонса
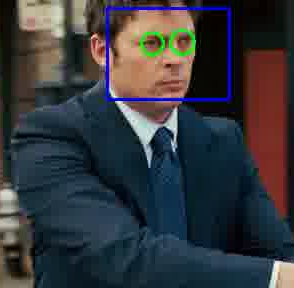
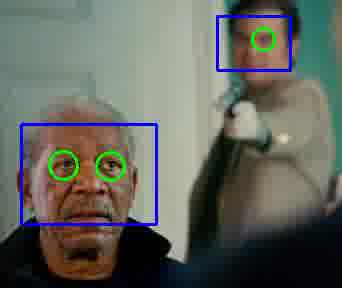
Рис.3: результат работы детектора лиц Виолы-Джонса
5. Свёрточная сеть
Далее рассмотрим модель классификатора изображений под названием свёрточная искусственная нейронная сеть(convolutional neural network, CNN). Особенностью этой модели классификатора есть встроенный механизм извлечения признаков из изображения. Он является частью сети и "самонастраивается" в процессе обучения сети. Подробнее о свёрточной нейронной сети можно почитать в статье [11].6. Локализация объектов
В этом разделе мы поговорим о задаче локализации объектов на изображении, которую можно неформально сформулировать в виде двух вопросов: есть ли объект на изображений и какую область изображения он занимает ? Эту задачу можно решать с помощью метода скользящего окна (sliding window) [12], схема которого выглядит следующим образом.- определить размер $w$ окна (исследуемой области изображения)
- собрать учебный набор $L$ из позитивных (на картинке есть объект) и негативных (на картинке нет объекта) примеров, размер учебных картинок должен соответствовать размеру $w$ окна
- обучить классификатор $c$ на полученном наборе $L$
- получить изображение для исследования,
выбрать шаг сдвига окна $d$ (по горизонтали и вертикали)
и коэффициент масштабирования изображения $s$ - разместить окно $w$ в крайнем положении (левый верхний угол) на исследуемом изображении
- выполнить классификацию текущего окна,
если классификатор $c$ определил наличие объекта в текущем окне,
то поместить параметры окна (текущее положение окна, масштаб изображения и значение выданное классификатором) в список результатов $R$ - если окно не достигло конечного положения (правый нижний угол),
то сдвигаем окно на шаг $d$ и переходим на предыдущий пункт
иначе переходим на следующий пункт - если размер изображения превышает размер $w$ окна
то масштабируем изображение с коэффициентом $s$ и переходим на п.5
иначе конец работы

Рис.4: неочищенный результат работы детектора

Рис.5: очищенный результат работы детектора
OpenCV 3.2.0 [i] собираем данные ... data/pgm/train/pos/pos-435.pgm data/pgm/train/pos/pos-329.pgm .... data/pgm/train/neg/neg-453.pgm размер: (450,) учебных: 840 контрольных: 0 тестовых: 210 [i] обучаем классификатор ... [i] тестируем классификатор ... количество ошибок на тестовом наборе: 2 из 210 1/108: data/pgm/detector-test/2/test-54.pgm 2/108: data/pgm/detector-test/2/test-52.pgm ..... 108/108: data/pgm/detector-test/2/test-37.pgm
Литература
-
Wikipedia: Histogram of oriented gradients
- http://en.wikipedia.org/wiki/Histogram_of_oriented_gradients -
Wikipedia: Scale-invariant feature transform
- http://en.wikipedia.org/wiki/Scale-invariant_feature_transform -
Антон Конушин Компьютерное зрение (2011). Лекция 8. Поиск и локализация объектов.
- http://www.youtube.com/watch?v=I1AiFF6ZkaE -
MathWorks: Image Classification with Bag of Visual Words
- http://www.mathworks.com/help/vision/ug/image-classification-with-bag-of-visual-words.html -
Борисов Е.C. Автоматизированная обработка текстов на естественном языке.
- http://mechanoid.kiev.ua/ml-text-proc.html -
Борисов Е.C. Кластеризатор на основе алгоритма k-means.
- http://mechanoid.kiev.ua/ml-k-means.html -
Е.С.Борисов Классификатор на основе машины опорных векторов.
- http://mechanoid.kiev.ua/ml-svm.html -
Wikipedia: Haar-like features
- http://en.wikipedia.org/wiki/Haar-like_features -
P.Viola,M.Jones Robust Real-Time Face Detection
- http://www.vision.caltech.edu/html-files/EE148-2005-Spring/pprs/viola04ijcv.pdf -
Е.С.Борисов Бустинг - композиции классификаторов
- http://mechanoid.kiev.ua/ml-adaboost.html -
Е.С.Борисов Классификатор изображений на основе свёрточной сети.
- http://mechanoid.kiev.ua/ml-lenet.html - Joseph Howse, Joe Minichino Learning OpenCV 3 Computer Vision with Python - Second Edition, Packt Publishing, September 2015, Packt Publishing, ISBN: 9781785289774
